Building AI agents in production
What we've built so far, lessons learned, and what's next
Hey Hitchhikers,
It’s been a while since we’ve posted an update in this newsletter as we’ve been heads down working on our new startup, Parcha. You may have also noticed a few changes in this newsletter which is now officially part of the Parcha brand. We will be cross-posting here and on our company blog moving forward.
In this update, we’re going to share a deep dive on what we’ve learned as we brought our AI product from demo into production. Before we jump in, a quick reminder to subscribe to our newsletter to get updates on our work at Parcha and how AI is changing the way we live, work and play.
For the past six months at Parcha, we have been building enterprise-grade AI Agents that instantly automate manual workflows in compliance and operations using existing policies, procedures, and tools. Now that we have the first set of Parcha agents in production for our initial design partners, here are some reflections and the lessons we have learned.
What do we call an “AI Agent”?
An agent is fundamentally software that uses Large Language Models to achieve a goal by constructing a plan and guiding its execution. In the context of Parcha, these agents are designed with certain components in mind. Let's explore them in more detail.
The agent specifications and directives
This is the agent's profile and basic instructions about how they operate. Agents have expertise in a particular topic or field; they have a role and means to do a job. They also have tools and commands they can use to perform their job. Here is a simple example of the specifications of an agent:
Profile: You are an Expert Assistant, an AI assistant trained by Parcha.ai to help users answer questions and complete tasks that require subject-matter expertise. You are assisting a Know Your Business (KYB) operations specialist in this conversation.
Directives and constraints: You share your thought process as you answer a question; you always use commands available to answer questions. If you are unsure how you previously did something or want to recall past events, thinking about similar events will help you remember. Do not make things up. If you don't know the answer or you don't have sufficient information, immediately say so via a clarification question.
Tools or commands: these can be other calls to language models (e.g. to summarize a document) or API calls to third parties (e.g. verify an address using the Google Maps API). For example, these are the commands for an agent responsible for performing address verification:
Commands:
1. address_verification
Command description: This tool is used by agents to verify a business physical address (nor URL). The address could be physical, virtual, a PO Box, etc.
args: "tool_input": {'type': 'string'}
2. company_detailed_risk_profile_tool
Command description: This tool is used by agents to assess the risk profile of a company.
args: "website": {'title': 'Website', 'description': 'the domain or name of the company', 'type': 'string'}The scratchpad
This is a space in the prompt to the language model where the agents add results from tools and observations as they execute their plan. These observations are used as tool inputs to guide the execution plan or the final assessment.
Example of the scratchpad for an agent that performed one of the commands above:
System: Command kyb_applicant_data_tool returned:
{'answer': "ACME CORP is a personal finance platform founded in 2015. It has over 250 employees and is headquartered in Chicago, Illinois. It offers investment, borrowing and spending tools to hundreds of thousands of customers and manages over $6 billion in assets. The company's website is acme.com and it can be contacted at support@acme.corp"}A Standard Operating Procedure (SOP)
An SOP is a set of instructions the agent needs to perform to complete a task. The agent uses the SOP to construct a plan using the available tools and to assess if it has all the information needed to make an assessment.
Here is an example of a simple SOP used to perform Know Your Business in a customer:
When a new company is onboarding onto BaaS’s Issuing platform, we are required to complete a KYB (Know Your Business) check on the customer based on FinCEN regulations. To complete the check we must carry out each of the following steps:
Company information: Get all the company information you have for the given company you wish to complete onboarding for. This information should include company address, beneficiary owners, website address etc.
Verify Business Registration: Confirm that the business is registered in the state where they claim to be. This can be done by checking with the Secretary of State of the state where the business is registered or using an SoS verification tool.
Verify Business Address: Confirm the business's operating address or addresses. The operating address may be different from the registered address. The business address can often be confirmed through business lookup tools like Google Places.
Check Watchlists and Sanctions Lists: Verify that the business is not listed on any watchlists, sanctions lists, or are otherwise involved in criminal activity. This can be done by using a business watchlist tool.
Check Business Description: Verify that the description of the business provided by the customer matches the actual business operations. This can be done by reviewing the business's website and comparing it to the description provided.
Check Card Issuer Rules: Review the use case that the business describes for Using our platform and confirm that it is compliant with the card issuer rules.
Final assessment instructions
Our agents have specific instructions that dictate the output of the agent. This could be an assessment of approving/denying/escalating to humans an application, writing a report based on the observations retrieved, or a specific output the user wants to action on.
Example of the Know Your Business final assessment:
Provide Detailed Report: If any of the checks do not pass, prepare a detailed report outlining which checks did not pass and why. Provide a recommendation on whether to approve the customer or whether further review is needed based on these findings. The final answer should include the detailed report and a recommendation.
How we started
Our initial approach to building agents was fairly naive. Our objective was to see what was possible and validate that we could build AI agents using the same instructions humans would use to perform the task. The agent was simple: we used Langchain Agents with a standard operating procedure (SOP) embedded in the agent’s scratchpad. We wrapped custom-built API integrations into tools and made them available to the agent. The agent was triggered from a web front-end through a websocket connection, which stayed open, receiving updates from the agent until it completed a task. While this approach helped us get something built quickly to get validation from our design partners, the approach had multiple setbacks we had to improve over time to prepare our agents to perform production-grade tasks.
Some of the particular setbacks of this approach include:
- Websocket connections caused many reliability issues and ended up not being the best tool for communication between our agents and their operators. We initially envisioned our agents as bi-directional, able to have a two-way conversation. In practice, after the initial interaction (when an operator asks an agent to perform a task like “do a KYB process on X customer”), the agent updates the customer until it completes the process. We may still want to correct an agent or ask for follow-up tasks. Still, there are simpler ways to handle communication for this mostly uni-directional interaction. Our customers didn’t need a chatbot; they needed an agent to complete a job.
- As we started testing our agents with our design partner’s SOPs, we realized it would take more than embedding the full text of instructions into one agent and hoping for the best. The agent would confuse tools or skip tasks. As more steps were performed and results were added to the scratchpad, the context window would be full of noise that the agent would not parse well. Finding the SOP or parsing results that would be useful in the next steps became a challenge.
- Similarly, we relied on the scratchpad as a simple means of “memorizing” information. Many times, the agent would not pick up the right piece of information from it and run a tool more than once so that it would gather input for a new step. This would make the agent way slower than it should be and inefficient.
- Our agents may take minutes to perform a complex task. Some tasks require doing OCR in multi-page documents, web crawling to research a particular topic, or calling multiple domain-specific APIs to cross-correlate information before concluding the SOP. Our initial approach had no recovery mechanism: if, after 3-4 minutes, a step would fail, the connection to the customer would drop, and the agent would have to be rerun. This, even for a POC, was a pretty poor customer experience.
- LLMs are stochastic, and as such, they can hallucinate, causing the agent to pick a tool that doesn’t exist or provide incorrect input to a tool. This would result in the workflow breaking and the task erroring out before completion.
- Finally, we were custom-building each agent without putting much thought to reusability. Tools were tightly coupled with their agents, and for the most part, each new agent we built required a new set of tools and API integrations we had to build from scratch.
Lessons learned
Agents as async, long-running tasks.
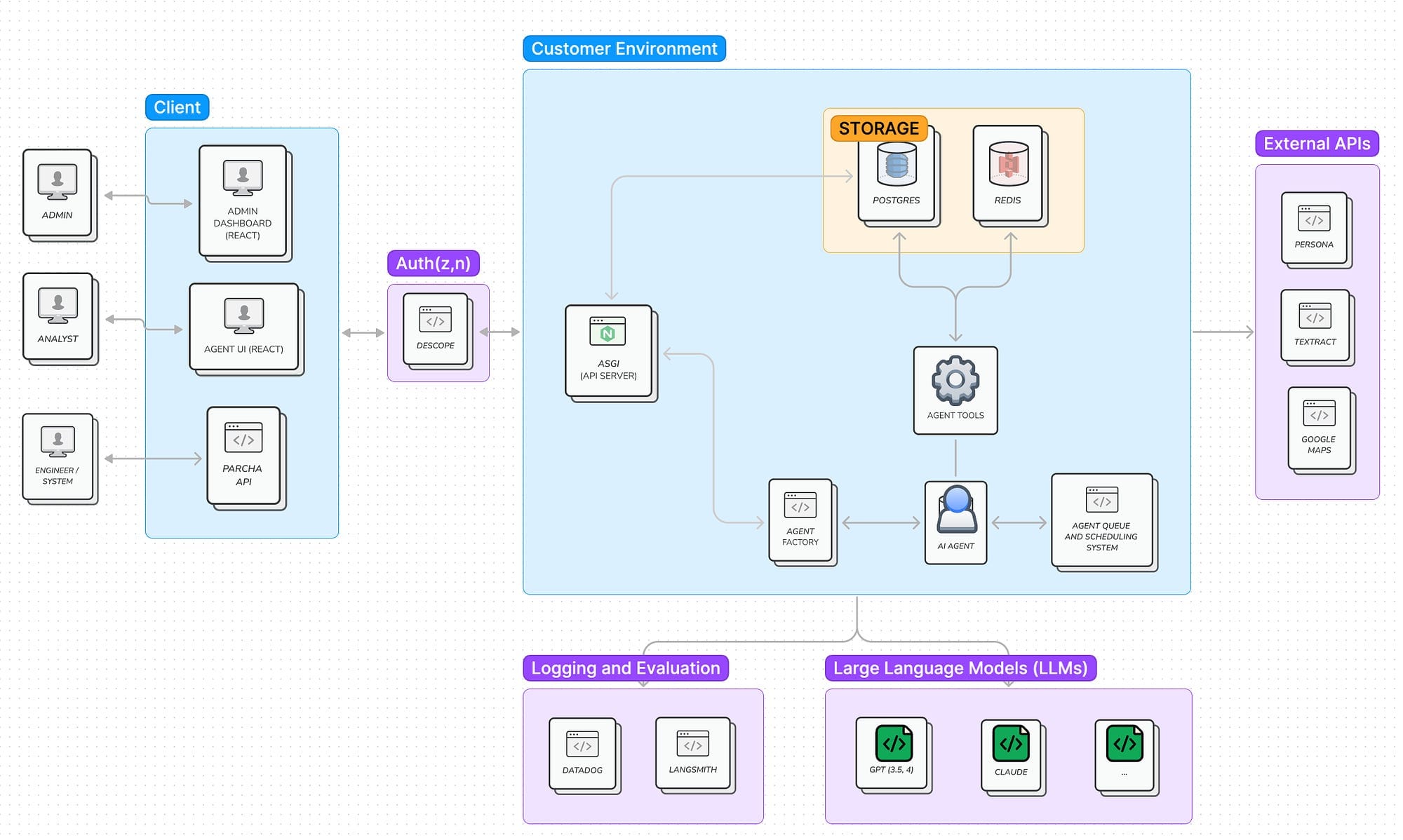
We now run our agents as long-running processes asynchronously. A web service can still trigger agents, but instead of communicating bi-directionally through WebSockets, they post updates using pub/sub. This helped us simplify the communication interface between the agent and the customer. It also made our agents more useful beyond a synchronous web service. Agents can still provide real-time status through server-sent events. They can still request actions from the customer, like asking for clarifications or waiting to receive a missing piece of information. Furthermore, agents can be triggered through an API, followed through a Slack channel (they start threads and provide updates as replies until completion), and evaluated at scale as headless processes. Since agents can be triggered and consumed through REST (polling and SSE), our customers can integrate them with their workflows without relying on a web interface.
Overview of Parcha’s agent architecture (October 2023)
Divide and conquer
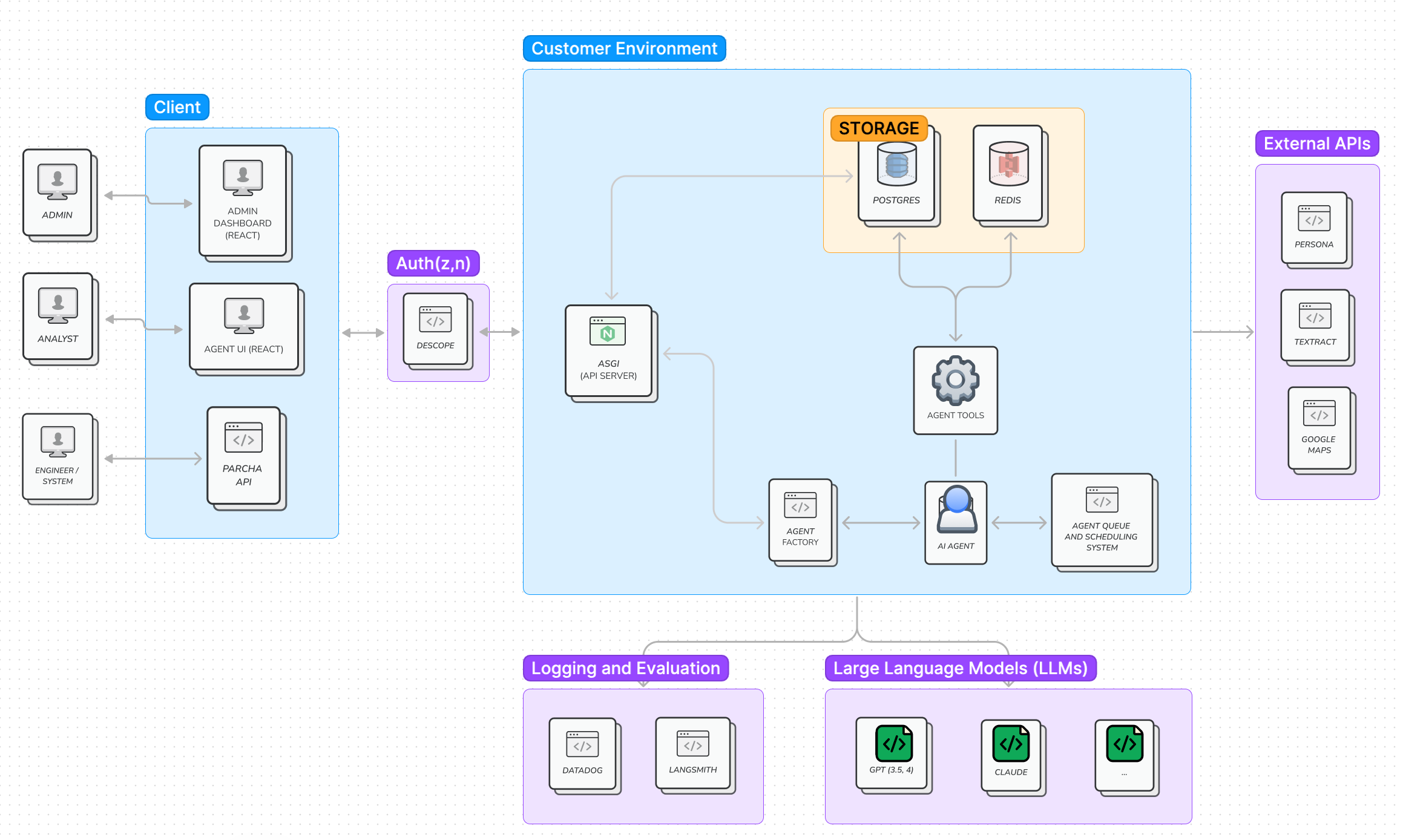
After evaluating multiple real-world SOPs and shadow sessions with design partners, we realized instructions could be decoupled into multiple SOPs. We developed the ability for agents to trigger and consume the output from other agents. Now, instead of adding a very complex SOP into one agent’s scratchpad, we have a coordinator <> worker model. The coordinator develops an initial plan using the master SOP and delegates subsets of the SOP to “worker” agents that gather evidence, make conclusions on a local set of tasks, and report back to the coordinator. Then, the coordinator uses all the evidence workers gather to develop a final recommendation.
For example, in a KYB process, it’s common to perform tasks like verifying the applicant's identity, verifying if a certificate of incorporation provided as a PDF is valid, and checking if the owners are on any watchlist. These are multi-step processes (checking the certificate involves performing OCR in the document, validating it, extracting information from it, and comparing it with the information provided by the applicant (usually fetched from an API). Instead of having one agent performing all these steps, a coordinator triggers a worker agent to perform each and report back. The coordinator would decide if - per the SOP - the customer should be approved or not. Since each agent has its scratchpad, this helped us steer them to complete tasks with less noise in the context window.
Context windows on single agent vs. coordinator/workers.
Don’t rush to judge
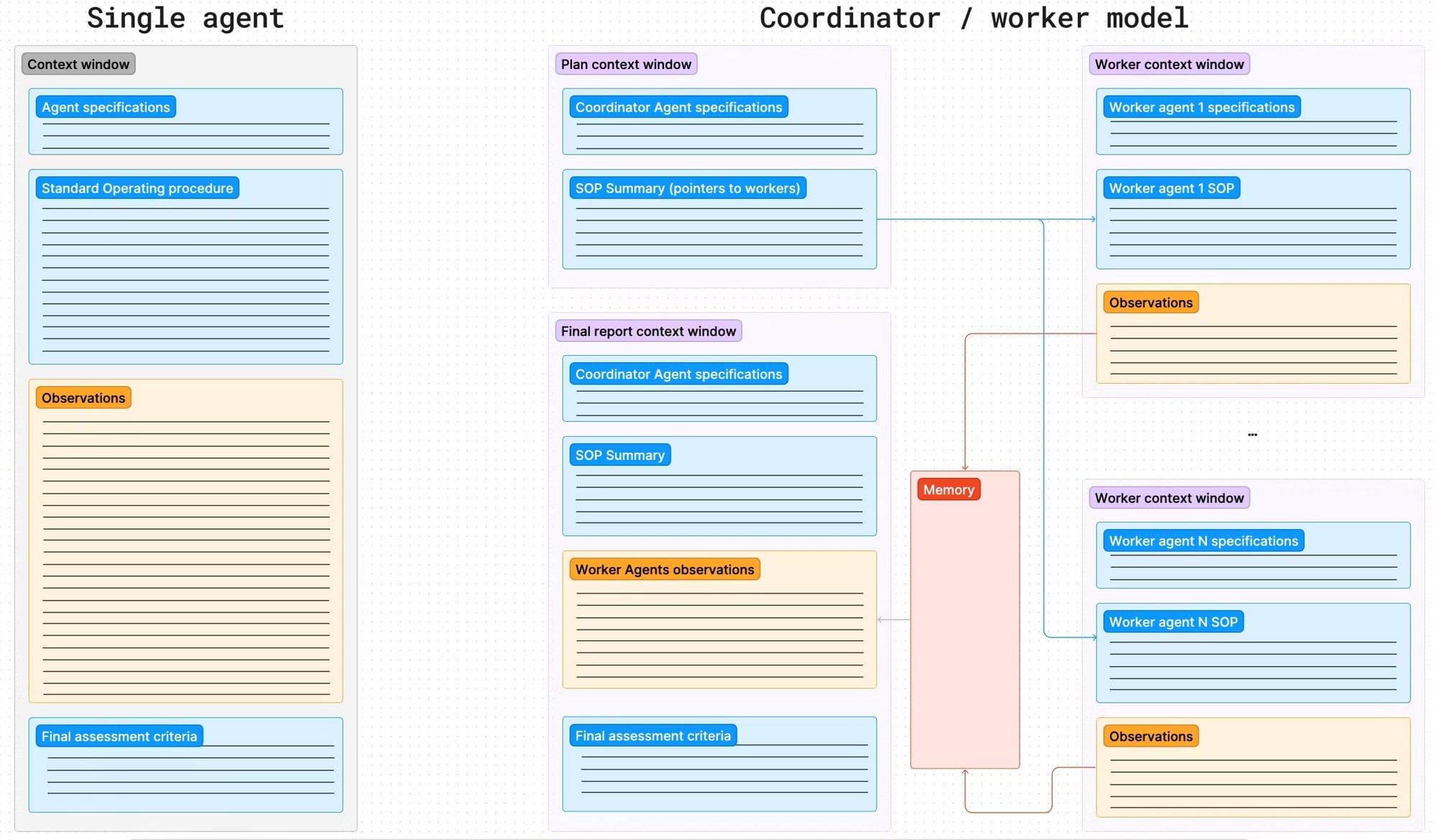
We faced a similar challenge when asking our Agents to verify information from a document. In the KYB example above, the customer enters information (e.g., company name) into a form and provides some evidence about it (e.g., an incorporation document). Our initial approach to a verification task using an LLM was to enter the text extracted from the document using OCR and the self-attested information into the context window and ask the LLM to verify if the information matched. Since documents are long and full of potentially irrelevant information, the results of such a task were not great. We made this significantly better by separating the extraction process from judgment. We now ask the LLM to extract the relevant information from the document (e.g., is it valid? What’s the company being mentioned, and which state/country is it incorporated in?). Then in a second trip to the LLM, we ask it to compare the information (removing the unnecessary elements from the document) from the self-attested information (e.g., the company information entered in the form). This not only worked way better but also didn’t increase token count or execution time significantly since the second step has a significantly reduced amount of prompt tokens in it.
Context window length, the complexity of the extraction, and judgment
Keep it simple
The coordinator <> worker agent model introduced a challenge: since each agent has a scratchpad, how do we share information? We had agents who needed the same information for two tasks, and initially, they both had to execute the same tools. This was inefficient. The obvious answer was to incorporate memory. There are a lot of mechanisms for memory in agents or LLM apps out there: using vector DBs, adding a subset of the previous steps into the scratchpad, etc. Rather than complicating our stack or risking polluting the scratchpad with noise, we decided to leverage an in-memory store we were already using for communication, Redis. We now tell the agent pieces of information they have available (the keys to the information in Redis) and built our tool interface to incorporate pulling inputs from the in-memory store. By only adding relevant memory to the scratchpad, we save on LLM tokens, keep the context window clean, and ensure any worker agents pick the right information whenever needed.
Human: Here are memories that you can provide to tools if they need them. These memories SHOULD NOT impact what step you pick next in the plan
{'identity_verification_api_full_name': 'John Doe', 'data_loader_tool_application_documents': '[{"name": "ID_VERIFICATION-ID-272905.pdf", "url": "http://example.com/file.pdf"}], 'digifi_data_loader_tool_self_attested_full_name': 'John Doe'}
...
"command": {
"instruction": "Verifying identity document",
"name": "identity_verification",
"args": {
"doc_url": "http://example.com/file.pdf",
"self_attested_values": {
"full_name_1": "John Doe"
}
}
}Example of relevant memory injected into the prompt as needed
Mistakes happen
Each Parcha agent interacts with multiple homegrown libraries and third-party services. Since the workflows are complex, there are cases where a step fails. An HTTP connection to an API may return an internal error, or the agent may choose the wrong input for a tool. Given how our agents were configured, any error would cause the agent to fail with no opportunity to recover. We now treat agents as asynchronous services with multiple failover mechanisms. They are queued and executed by worker processes (we use RQ for this), and we get alerted when they fail. More importantly, we are now leveraging well-typed exceptions in our tools to feed them back to the agent. If a tool fails, we send the exception name and message to the agent, allowing it to recover independently. This has helped us reduce the number of catastrophic failures significantly.
System: Command digifi_data_loader_tool returned:
Unable to execute command due to an error:
1 validation error for DataLoaderInput
display_id field required (type=value_error.missing)
Human: The tool returned an error. If the error was your fault, take a deep breath and try again. If not, escalate the issue and move on.
Example of self-correction prompt sent to the agent with exception name and messageBuilding blocks
After taking multiple weeks to develop each of our first set of agents, we decided to focus on reusability and speed of building. We want to enable our customers to build their agents quickly. To that end, we developed our agent and its tools interface, focusing on composability and extensibility. We now also have enough workflows from design partners to understand which building blocks we need to invest in. For example, many of our customers do some document extraction. We now have a tool that can easily be applied to any document extraction task. We built this tool once but already use it in most workflows. Our customers can use it to extract information from an incorporation document and validate its veracity or to calculate an individual's income from a pay stub. The work to adapt the tool to one specific, new workflow is minimal.
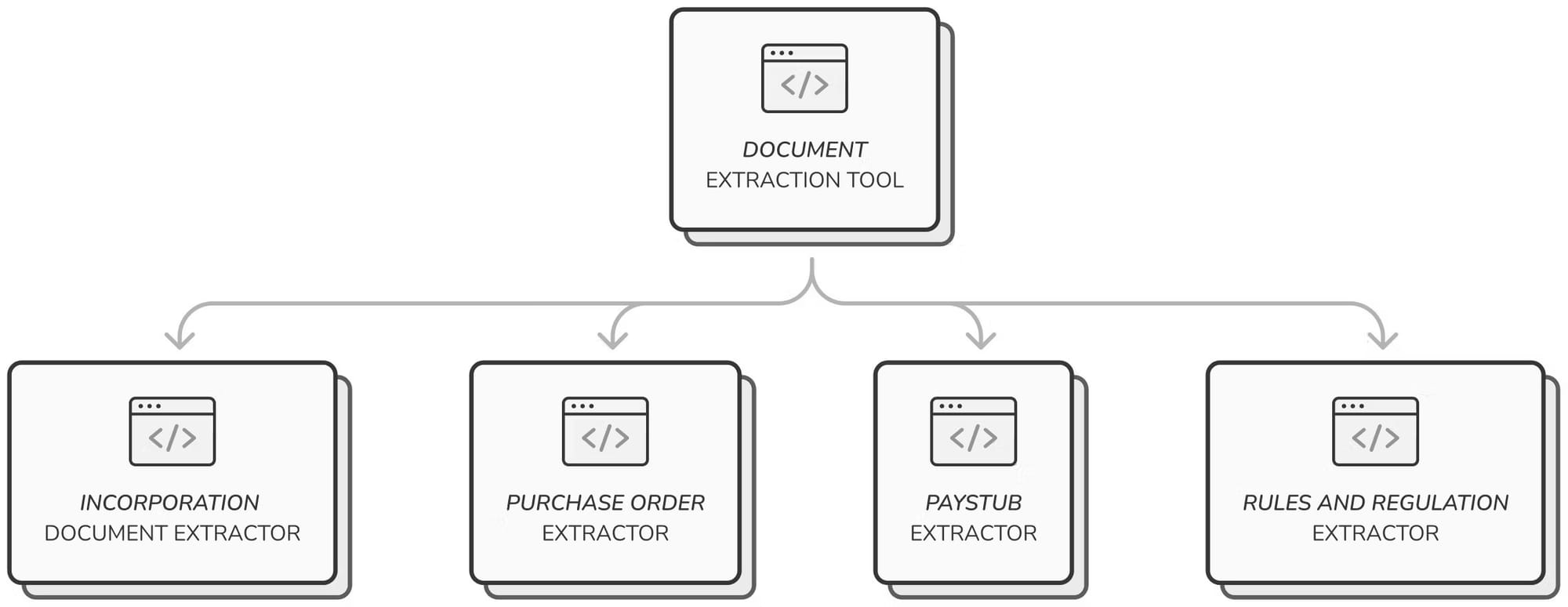
Our document extractor tool can be easily extended into multiple use cases
What's Next
- Webhook triggers to run an agent and perform actions on its final assessment, enabling end-to-end automation for our customers.
- Implementing our in-house robust agent benchmarks, assessing the capabilities of our agents to Plan, Execute, be Accurate, and Reasoning (PEAR, we’ll write about it).
- Deploy agents and tools as micro-services. By training our agents to create and perform complex execution plans (essentially DAGs), we could orchestrate them as asynchronous micro-services, which will increase composability and enable agents to use language-agnostic tools while enabling our tools to be compatible with agents outside of Parcha.
Want to build with us?
We are hiring a full-stack founding engineer in San Francisco. This person will be responsible for leading the architecture and development of the platform powering our AI Agents. They will partner with our founders and AI engineers to build bleeding-edge technology for real enterprise customers. Learn more about this role here and contact miguel (@miguelriosEN on X or miguel@parcha.ai).